Design principles for eva#
Eva, standing for evaluation and verification of the analysis, is a comprehensive tool designed to facilitate the process of evaluating data assimilation systems. Below we outline the general design that has been adopted for eva.
Custom reading, unified backend#
Data comes in many different formats with different properties. For example, when evaluating a data assimilation system, data in observation space would need to be evaluated at the same time as gridded increments and statistics written to a log file. In eva, data ingest classes can be constructed for data of any type, but to ensure consistency these readers are required to translate data into a common eva data structure. Since the data structure is the same regardless of the starting point a single set of classes can be used to plot data from different sources.
In eva Xarray is chosen for this backend data structure. Xarray has much support for Earth science applications and is integrated with cloud technologies such as Dask.
Eva creates an object of its DataCollections class to hold the data that can be read by the various data ingest classes. The class contains several helper functions for adding new data to the object, accessing that data and displaying the contents.
Transforms#
Once data has been read in it may be necessary to transform it in order to create new variables or reformat the data to enable better visualization. Eva provides several transform classes that can be used to this effect. In each case the transforms only have access to the DataCollections object and they can modify its contents by adding new variables.
Plotting#
Once a user has created all the variables they need they can access the plotting backends that eva supports. Currently eva can make plots using Matplotlib via the EMCpy library or it can make Bokeh plots via the hvPlot library.
Batch and interactive processing#
In many cases users are running a workflow system that might run for several days or months of simulation time without user intervention. As well as running the programs to integrate the forecast these workflows are responsible for outputting the data in a human digestible form for evaluation. Later on the user may delve deeper into the output to learn more or perform specific evaluation.
Eva is designed to support this range of evaluation. It can be run in batch mode, where only a YAML is used to dictate everything it does or it can be run interactively where a user manipulates data on the fly. YAML files are intended as more human readable forms of dictionaries, like those used throughout Python, and they are. However, very long YAML files can be difficult to interpret, can have hard to debug syntax errors and do not make for a particularly ‘human’ way of working. In addition, each time you need to make a change to the YAML the entire program needs to be run again, reducing the efficiency of the user’s development cycle. When running interactively the user will have access to stripped down APIs for each component of eva and the program will remain active so more variables can be added and plotted without the need to re-read.
Eva is provided with several example YAML files showing how to use the various ingest classes, transforms and batch plotting tool. It is also provided with several Jupyter notebooks that show how to access the same classes using single line APIs interactively.
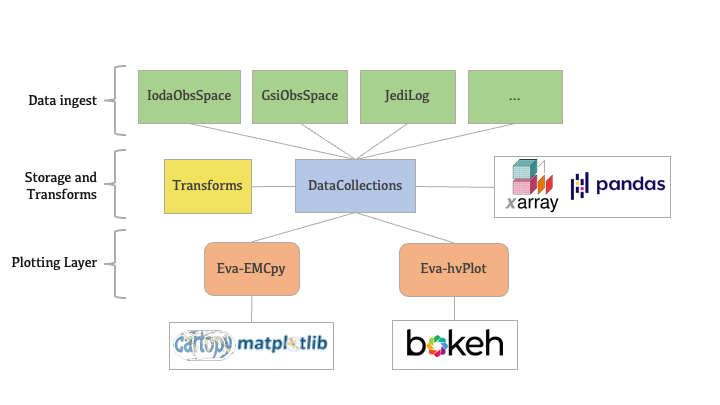
Graphical representation of the eva structure#
The below figure shows a graphical representation of the eva structure, showing the unified data holding class central to the design. Other components interact with the data in that object to enable the plotting of data of different formats with the same APIs.